¿Qué es un Data Lakehouse?
Durante la última década, las empresas han estado invirtiendo fuertemente en su estrategia de datos para poder obtener información relevante y utilizarla en la toma de decisiones críticas. Esto les ha permitido reducir costos operativos, predecir ventas futuras y tomar acciones estratégicas.
¿Qué hace un Data Lakehouse?
Como su nombre lo indica, una arquitectura de data lakehouse combina un data lake y un data warehouse. Sin embargo, no se trata solo de una mera integración entre ambos, sino de aprovechar lo mejor de cada arquitectura: las transacciones confiables de un data warehouse y la escalabilidad y el bajo costo de un data lake.
Existen cuatro problemas clave en el mundo de la arquitectura de datos que los data lakehouses abordan:
- Resuelven los problemas relacionados con los almacenes de datos al proporcionar un repositorio centralizado para almacenar y gestionar grandes volúmenes de datos estructurados y no estructurados.
- Eliminan la necesidad de movimientos de datos complejos y que consumen mucho tiempo, reduciendo la latencia asociada con la transferencia de datos entre sistemas.
- Permiten a las organizaciones realizar un procesamiento de datos rápido y eficiente, facilitando el análisis y la toma de decisiones basada en los datos.
- Finalmente, un data lakehouse proporciona una solución escalable y flexible para almacenar grandes volúmenes de datos, permitiendo a las organizaciones gestionar y acceder fácilmente a su información a medida que sus necesidades crecen.
Los data warehouses están diseñados para ayudar a las organizaciones a gestionar y analizar grandes volúmenes de datos estructurados.
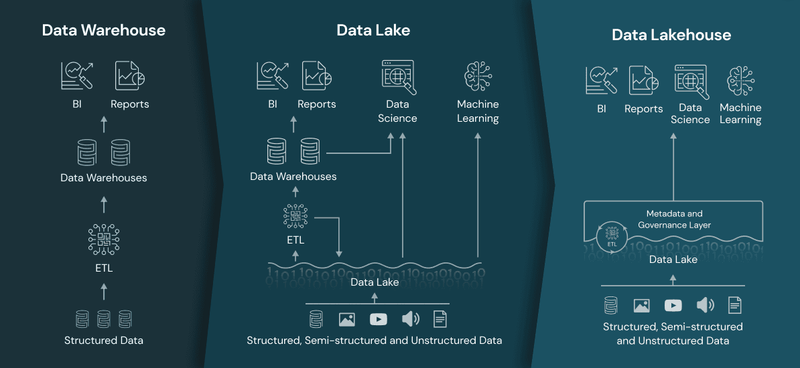
¿Cómo funciona un Data Lakehouse?
Un data lakehouse opera utilizando una arquitectura multinivel que integra los beneficios de los data lakes y los data warehouses. Comienza ingiriendo grandes volúmenes de datos en bruto, incluyendo formatos estructurados y no estructurados, en el componente de data lake. Estos datos en bruto se almacenan en su formato original, lo que permite a las organizaciones conservar toda la información sin perder ningún detalle.
A partir de ahí, se pueden realizar procesos avanzados de transformación y procesamiento de datos utilizando herramientas como Apache Spark y Apache Hive. Los datos procesados luego se organizan y optimizan para consultas eficientes en el componente de data warehouse, donde pueden ser fácilmente analizados mediante herramientas basadas en SQL.
El resultado es un repositorio centralizado para la gestión de Big Data que permite una exploración, análisis e informes rápidos y flexibles. La infraestructura escalable del data lakehouse y su capacidad para manejar diversos tipos de datos lo convierten en un recurso valioso para las organizaciones que buscan aprovechar al máximo su Big Data.
Elementos de un Data Lakehouse
Los data lakehouses cuentan con una variedad de elementos para satisfacer las necesidades de gestión y análisis de datos de las organizaciones.
- Un elemento clave es la capacidad de almacenar y procesar distintos tipos de datos, incluyendo datos estructurados, semiestructurados y no estructurados.
- Proporcionan un repositorio centralizado para almacenar datos, permitiendo a las organizaciones guardar toda su información en un solo lugar, lo que facilita su gestión y análisis.
- La capa de gestión de datos permite gobernar, asegurar y transformar los datos según sea necesario.
- La capa de procesamiento de datos ofrece capacidades de análisis y aprendizaje automático, permitiendo a las organizaciones analizar sus datos de manera rápida y eficiente para tomar decisiones basadas en datos.
- Otro elemento importante de un data lakehouse es su capacidad para ofrecer procesamiento y análisis en tiempo real, lo que permite a las organizaciones responder rápidamente a cambios en las condiciones del negocio.
Características clave de un Data Lakehouse
Los data lakehouses presentan características que los hacen una solución robusta para la gestión de datos:
- Soporte para transacciones: Permiten transacciones ACID, garantizando la consistencia mientras varias partes acceden y modifican los datos de manera concurrente, generalmente usando SQL.
- Aplicación y gobernanza de esquemas: Admiten la aplicación y evolución de esquemas, permitiendo arquitecturas de esquema en estrella o copo de nieve, asegurando la integridad de los datos con mecanismos sólidos de gobernanza y auditoría.
- Soporte para BI: Permiten el uso de herramientas de Business Intelligence (BI) directamente sobre los datos de origen, reduciendo la latencia y evitando la necesidad de copias separadas en un data lake y un data warehouse.
- Desacoplamiento de almacenamiento y cómputo: Al usar clústeres separados, estos sistemas pueden escalar a más usuarios concurrentes y manejar grandes volúmenes de datos.
- Apertura: Utilizan formatos de almacenamiento abiertos y estandarizados, como Parquet, y ofrecen API para acceso eficiente desde diversas herramientas y motores, incluyendo machine learning y bibliotecas de Python/R.
- Compatibilidad con múltiples tipos de datos: Pueden manejar imágenes, videos, audio, datos semiestructurados y texto.
- Soporte para diversas cargas de trabajo: Manejan casos de uso como ciencia de datos, machine learning, SQL y analítica avanzada, operando sobre un único repositorio de datos.
- Procesamiento en tiempo real: El soporte para streaming elimina la necesidad de sistemas dedicados exclusivamente a aplicaciones de datos en tiempo real.
Características empresariales adicionales
Los sistemas empresariales requieren herramientas adicionales, como:
- Seguridad y control de acceso.
- Gobernanza de datos: auditoría, retención y trazabilidad, fundamentales ante regulaciones de privacidad.
- Descubrimiento de datos: catálogos de datos y métricas de uso.
Con un lakehouse, todas estas características empresariales solo necesitan ser implementadas, probadas y administradas en un único sistema, reduciendo la complejidad y el costo operativo.