Big Data, Hadoop y ZooKeeper: Importancia, Componentes y Aplicaciones en la Computación Distribuida
En un contexto empresarial cada vez más digitalizado, la gestión efectiva de grandes volúmenes de datos se ha convertido en una necesidad estratégica. El crecimiento masivo de datos ha elevado la importancia de los sistemas Big Data, no solo como herramientas tecnológicas, sino como auténticos catalizadores para la toma de de cisiones informada y la generación de ventajas competitivas.
Big Data
Se trata de la gestión y análisis de enormes volúmenes de datos que no pueden ser tratados de manera convencional, ya que superan los límites y capacidades de las herramientas de software habitualmente utilizadas para la captura, gestión y procesamiento de datos.
En Big Data se conocen tres características denominadas “Las tres V de Big Data”
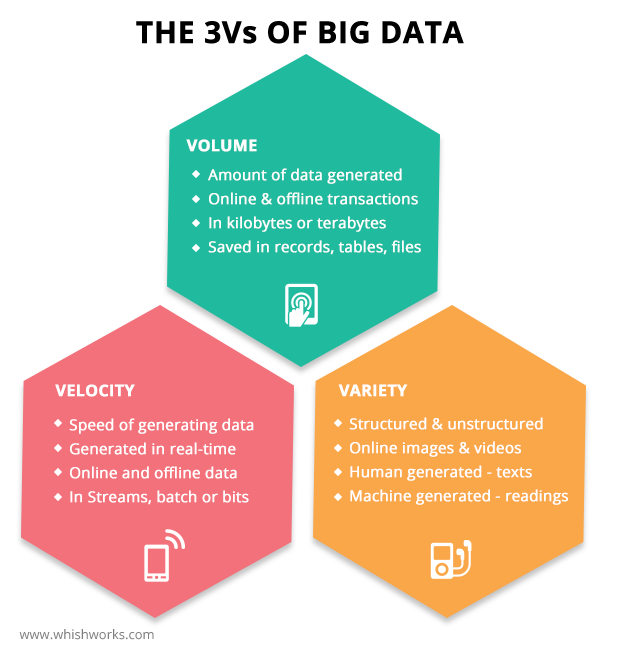
- Volumen: Cantidad de datos importa. Con big data, tendrá que procesar grandes volúmenes de datos no estructurados de baja densidad. Puede tratarse de datos de valor desconocido, como feeds de datos de Twitter,equipo con sensores, etc.
- Velocidad: Se refiere a la rapidez con la que estos nuevos datos están siendo generados y procesados.
- Variedad: La variedad hace referencia a los diversos tipos de datos disponibles (estructurados, no estructurados, etc.)
Surgieron dos "V" más durante los últimos años: valor y veracidad. Los datos poseen un valor intrínseco; sin embargo, no tienen utilidad hasta que dicho valor se descubre. Igualmente importante: ¿Cuán veraces son sus datos? ¿Cuánto puede confiar en ellos?
Alta disponibilidad
La alta disponibilidad es la capacidad que tiene un sistema para ser accesible y confiable casi todo el tiempo, lo cual elimina o disminuye el tiempo de inactividad. Combina dos conceptos para determinar si un sistema cumple con su nivel de rendimiento operativo: el primero tiene que ver con la accesibilidad o la disponibilidad prácticamente permanente de un servicio o servidor sin tiempo de inactividad; y el segundo se refiere a su funcionamiento según las expectativas razonables y duran te un período establecido. No se trata solo de cumplir con el tiempo de actividad indicado en el acuerdo de nivel del servicio (SLA) o con las expectativas establecidas entre el proveedor y el cliente, sino que implica que el sistema sea resistente, confiable y eficaz.
Computación paralela
La computación paralela es una estrategia de procesamiento que busca resolver problemas mediante la ejecución simultánea de múltiples instrucciones. Este enfo que, basado en la premisa de dividir problemas grandes en tareas más pequeñas resueltas en paralelo, ha sido fundamental en la computación de alto rendimiento. A medida que las limitaciones físicas han obstaculizado el aumento de la frecuencia de procesamiento, el interés en la computación paralela ha crecido, convirtiéndose en el paradigma dominante en la arquitectura de computadoras, especialmente a través de procesadores multinúcleo.
El consumo de energía y la generación de calor en las computadoras han generado preocupaciones, impulsando aún más la adopción de la computación en paralelo. Las computadoras paralelas se dividen en categorías según el nivel de paralelismo admitido por su hardware, desde procesadores multinúcleo en una sola máquina hasta clústeres y grids que utilizan varios equipos para tareas colaborativas.
Tradicionalmente, los programas informáticos se han diseñado para el cómputo en serie, ejecutando instrucciones secuenciales en una unidad central de procesamiento. Sin embargo, la computación en paralelo aborda esta limitación al ejecutar simultáneamente múltiples elementos de procesamiento para resolver un problema. Esto implica la división del problema en partes independientes, permitiendo que cada elemento de procesamiento ejecute su parte del algoritmo al mismo tiempo que los demás.
Los modelos de programación paralela son fundamentales para escribir y ejecutar programas en este contexto. La eficacia de un modelo se evalúa por su generalidad y rendimiento, considerando la eficiencia, precisión y velocidad de la ejecución. La implementación de modelos de programación puede adoptar diversas formas, como bibliotecas invocadas desde lenguajes secuenciales, extensiones del lenguaje o nuevos modelos completos de ejecución.
Es esencial lograr un consenso entre los modelos de programación para garantizar que el software desarrollado sea compatible con diversas arquitecturas. Para arquitecturas secuenciales, el modelo de von Neumann se destaca por proporcionar un puente eficaz entre hardware y software, permitiendo la compilación eficiente de lenguajes de alto nivel y su implementación eficaz en el hardware.
Además, en la clasificación de arquitecturas de computación paralela, se consideran diferentes modelos según la relación entre las instrucciones y los datos:
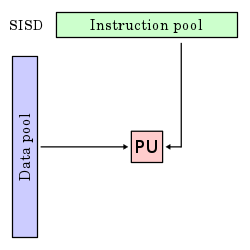
Una instrucción, un dato (SISD): En esta arquitectura, representada por la conocida Arquitectura Von-Neumann, un único procesador ejecuta un solo flujo de instrucciones para operar sobre datos almacenados en una única memoria. Este modelo, denominado “Single Instruction, Single Data” (SISD), se encuentra en computadoras secuenciales como los PC y antiguos mainframes. Aunque pue de aplicar técnicas como la segmentación o el pipelining, no explota el paralelismo en instrucciones ni flujos de datos.
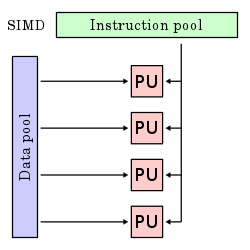
Una instrucción, múltiples datos (SIMD): En es te modelo, todas las unidades ejecutan la misma instrucción de manera sincronizada, pero con datos distintos. Este enfoque, conocido como “Single Instruction, Multiple Data” (SIMD), aprovecha varios flujos de da tos dentro de un único flujo de instrucciones para realizar operaciones paralelizadas de manera natural. Pue de adoptar formas de Arquitectura vectorial o matricial
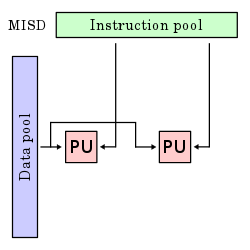
Múltiples instrucciones, un dato (MISD): Aun que poco común, el modelo “Multiple Instruction, Single Data” (MISD) se utiliza en situaciones de paralelismo redundante, como la navegación aérea, donde se re quieren varios sistemas de respaldo en caso de fallos. Aunque algunas arquitecturas teóricas han propuesto el uso de MISD, ninguna ha llegado a producirse en masa. Algunos autores incluyen en este modelo a las arquitecturas vectoriales supersegmentadas o vectorial escalar.
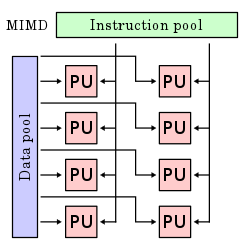
Múltiples instrucciones, múltiples datos (MIMD): Representando sistemas distribuidos, el modelo “Multiple Instruction, Multiple Data” (MIMD) implica varios procesado res autónomos que ejecutan simultáneamente instrucciones diferentes sobre conjuntos de datos distintos. Estos sistemas se clasifican como arquitecturas MIMD y pueden aprovechar un espacio compartido de memoria o uno distribuido
En conjunto, estas arquitecturas ofrecen un panorama completo de las estrategias para gestionar el paralelismo en el procesamiento de datos e instrucciones, abordando diferentes necesidades y aplicaciones en el ámbito de la computación paralela.
Computación distribuida
La computación distribuida emerge como un modelo fundamental para abordar problemas de computación masiva, aprovechando la capacidad de un gran número de ordenadores organizados en clústeres dentro de una infraestructura distribuida.
En este contexto, la computación distribuida se materializa en proyectos solidarios que aprovechan la participación de miles de ordenadores voluntarios conectados a través de Internet. Estos sistemas se basan en la descentralización de la información mediante software descargado por el usuario, distribuyendo cálculos entre los diversos ordenadores. El resultado, una vez obtenido, se envía de vuelta al servidor. Esta colaboración permite alcanzar cuotas de procesamiento notables, a menudo superando las capacidades de superordenadores y a un costo considerablemente menor.
Uno de los principales beneficios de la computación distribuida es la capacidad de asignar la actividad de procesamiento a ubicaciones donde se pueda realizar con mayor eficiencia. Este enfoque se puede ilustrar en el ámbito empresarial, donde cada oficina puede organizar y manipular datos para satisfacer necesidades específicas, compartiendo luego los resultados con el resto de la organización. Además, facilita la optimización de equipos y mejora el equilibrio del procesamiento dentro de una aplicación, una consideración crucial dado que algunas aplicaciones requieren capacidad de procesamiento que no puede ser proporcionada por una sola máquina.
La computación distribuida se materializa en la ejecución conjunta de varias computadoras para abordar problemas comunes, convirtiendo una red de computadoras en una única entidad poderosa capaz de afrontar desafíos complejos. Este enfoque encuentra aplicación en diversas áreas, como el cifrado de grandes volúmenes de datos, la resolución de ecuaciones físicas y químicas complejas con múltiples variables, y la renderización de animaciones tridimensionales de alta calidad.
Entre las ventajas de los sistemas distribuidos, se destacan:
- Escalabilidad: Los sistemas distribuidos pueden crecer según las necesidades, permitiendo la adición de nuevos nodos de computación a medida que sea necesario.
- Disponibilidad: La tolerancia a fallos permite que el sistema continúe en funcionamiento incluso si una de las computadoras falla, evitando colapsos.
- Consistencia: A pesar de la duplicación de datos entre computadoras, el sistema gestiona automáticamente la coherencia de datos.
- Transparencia: Proporciona una separación lógica entre el usuario y los dispositivos físicos, permitiendo interactuar con el sistema como si fuera una única computadora.
- Eficiencia: Ofrece un rendimiento rápido y utiliza de manera óptima los recursos del hardware subyacente, gestionando cualquier carga de trabajo sin preocuparse por fallos del sistema.
En términos de arquitecturas distribuidas, existen diferentes modelos, entre ellos:
- Arquitectura cliente-servidor: Divide las funciones entre clientes y servidores, siendo estos últimos responsables de administrar la mayoría de los datos y recursos.
- Arquitectura de tres niveles: Divide las máquinas servidoras en servidores de aplicaciones (lógica de la aplicación) y servidores de bases de datos (almacenamiento y administración de datos), reduciendo cuellos de botella.
- Arquitectura de nivel N: Incluye varios sistemas cliente-servidor que se comunican para resolver un problema común, común en sistemas distribuidos modernos.
Apache Hadoop
Apache Hadoop es un entorno de trabajo para software para programar aplicaciones distribuidas que manejen grandes volúmenes de datos (big data). Permite a las aplicaciones trabajar con miles de nodos en red y petabytes de datos. Hadoop se inspiró en los documentos de Google sobre MapReduce y Google File System (GFS).
Hadoop, en lugar de utilizar un equipo grande para procesar y almacenar los datos, Hadoop facilita la creación de clústeres de hardware de consumo para analizar con juntos de datos masivos en paralelo, es decir implementa procesamiento en paralelo a través de nodos de datos en un sistema de ficheros distribuidos.
Uno de los puntos fuertes de Hadoop es que está diseñado para ejecutarse en ser vidores de bajo coste y que dispone de una gran tolerancia a fallos. De hecho, en Hadoop, los fallos de hardware se tratan como una regla y no como una excepción. Hadoop en un entorno que suministra librerías open source para la computación distribuida usando varios componentes como "Hadoop Common", "MapReduce", "Hadoop Distributed File System (HDFS)"
Hadoop Common
El módulo Hadoop Common pone a disposición de todos los demás elementos del framework un set de funciones básicas, entre las cuales se encuentran los archivos.jar de Java necesarios para iniciar Hadoop, las bibliotecas para la serialización de datos así como las interfaces para el acceso al sistema de archivos de la arquitectura Hadoop y la llamada a procedimiento remoto (remote procedure call o RPC) para la comunicación entre clientes dentro de un clúster. Además, el módulo también contiene el código fuente, la documentación del proyecto e información sobre otros proyectos de la comunidad Hadoop.
De manera breve y concisa, Hadoop Common o Hadoop Común es el encargado de administrar el acceso a la serie de bibliotecas y servicios que posee Hadoop.
HDFS
HDFS es un sistema de archivos distribuido que maneja grandes conjuntos de datos que se ejecutan en hardware básico. Se utiliza para escalar un solo clúster de Apache Hadoop a cientos (e incluso miles) de nodos. Se trata de un un sistema de almacenamiento tolerante a fallos que puede almacenar gran cantidad de datos, escalar de forma incremental y sobrevivir a fallos de hardware sin perder datos. Si un nodo fallase, el clúster puede continuar trabajando sin perder datos o interrumpir el trabajo.
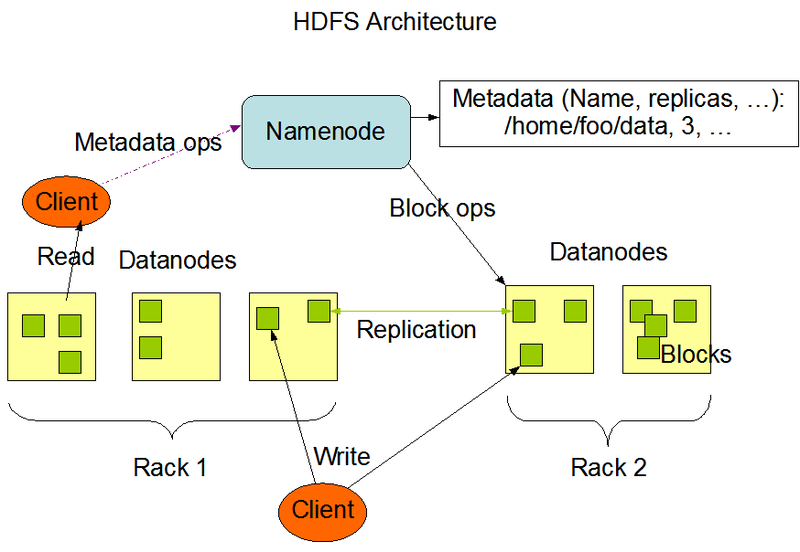
Entre los componentes de HDFS encontramos:
- NameNode: Todos los bloques en los DataNodes son gestionados por el Na meNode, que se conoce como el nodo maestro,actúa como el cerebro y la pieza central de HDFS. No almacena datos reales, sino metadatos: información sobre la estructura, ubicación y replicación de los datos. Este Realiza las siguientes funciones:
- Ejecuta las operaciones del espacio de nombres del sistema de archivos, como abrir, renombrar y cerrar archivos y directorios.
- El NameNode gestiona y mantiene los DataNodes.
- Determina la asignación de bloques de un archivo a DataNodes.
- El NameNode registra cada cambio realizado en el espacio de nombres del sistema de archivos.
- Guarda las ubicaciones de cada bloque de un archivo.
- El NameNode se encarga del factor de replicación de todos los bloques.
- El NameNode recibe informes de bloques de todos los DataNodes para asegurarse de que el DataNode esté activo.
- Si un DataNode falla, el NameNode elige nuevos DataNodes para las nuevas réplicas.
El NameNode almacena información sobre la ubicación de bloques, permisos, etc, en el disco local en forma de dos archivos:
- Fsimage: Fsimage significa “File System image” (imagen del sistema de archivos). Contiene el espacio de nombres completo del sistema de ar chivos Hadoop desde la creación del NameNode.Imaginemos el FSImage como una fotografía del sistema de archivos en un momento determinado. No contiene datos reales de los archivos, sino una representación jerárqui ca de los directorios y archivos en HDFS. Es crucial porque, en caso de fallo, esta “fotografía” puede usarse para restaurar el estado del sistema.
- EditLog: Contiene todos los cambios recientes realizados en el espacio de nombres del sistema de archivos hasta la Fsimage más reciente. Mientras que el FSImage es estático, el registro de Edits es dinámico y actúa como un diario. Cada vez que se realiza un cambio en HDFS (como crear un archivo), se añade una entrada a Edits. Sin embargo, consultar Edits para cada operación sería ineficiente, por lo que de vez en cuando, este registro se fusiona con el FSImage para reflejar el estado actual del sistema.
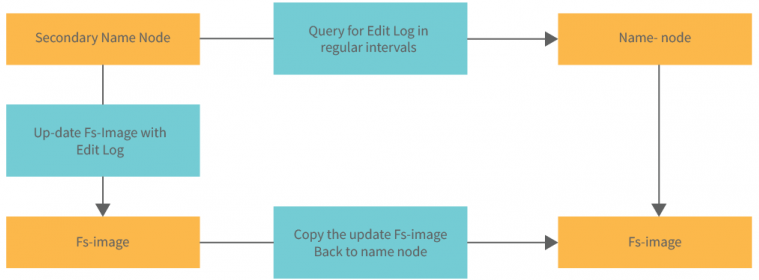
- Secondary NameNode: Aunque su nombre sugiere que podría ser una copia de seguridad del NameNode principal, no lo es. Su papel principal es facilitar el proceso de checkpointing y aliviar al NameNode principal de esta tarea. Checkpointing se le denomina al acto de combinar el FSImage con el regis tro de Edits para crear un nuevo FSImage se llama checkpointing. Si no se realiza este proceso,el registro de Edits podría crecer demasiado, lo que ralen tizaría el sistema y complicaría la recuperación en caso de fallo. El Secondary NameNode automatiza y maneja este proceso, obteniendo ambos archivos del NameNode principal, fusionándolos y luego devolviendo un FSImage actualizado al NameNode principal.
- DataNode: Estos nodos son los trabajadores del sistema y almacenan los datos reales. Cuando se guarda un archivo en HDFS, se divide en bloques de tamaño fijo, y esos bloques se distribuyen entre los DataNodes. Además, para garantizar la resistencia a fallos, cada bloque se replica en múltiples DataNodes. Cada DataNode informa regularmente al NameNode sobre los bloques que posee y su estado. Estos "informes de bloques" permiten al NameNode tener una visión global de la salud y ubicación de los bloques en el sistema.
- Bloques: Internamente, HDFS divide el archivo en trozos del tamaño de un bloque llamado bloque. El tamaño del bloque es de 128 MB de forma predeterminada. Se puede configurar el tamaño del bloque según los requisitos.
- Block Pools: Un Block Pool en HDFS es un conjunto de bloques que perte necen a un único sistema de nombres (NameSpace). Estos bloques almacenan los datos de los archivos del sistema de archivos correspondiente. Cada Block Pool sirve como una entidad independiente, lo que significa que no comparten bloques entre sí. Esta separación garantiza que un NameNode no interfiera con los bloques de datos de otro NameNode. Facilita la administración, el mantenimiento y la escalabilidad del sistema.
- Federación y Block Pools: La introducción de Block Pools está estrecha mente con la Federación en HDFS. La Federación es una característica que permite que HDFS tenga múltiples NameNodes independientes, don de cada NameNode tiene su propio espacio de nombres y su correspon diente Block Pool. Esta división permite escalar el sistema al distribuir el metadato y mejorar la disponibilidad.
- DataNodes y Block Pools: Aunque hay múltiples Block Pools en un sistema federado, un DataNode único puede servir a múltiples NameNodes y, por lo tanto, puede gestionar bloques de varios Block Pools. Esto per mite una utilización eficiente del espacio de almacenamiento y reduce la necesidad de replicar DataNodes para cada Block Pool.
Aunque cada NameNode gestiona su propio espacio de nombres y Block Pool, todos los NameNodes comparten la misma infraestructura subyacente de DataNodes. Esto significa que mientras los metadatos están separados y aislados, los datos reales están distribuidos y replicados a través del mismo conjunto de DataNodes en el clúster.
Mapreduce y Yarn
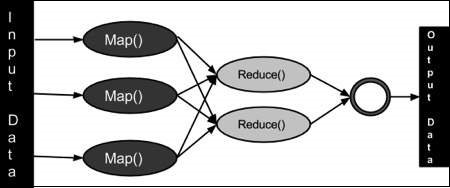
Hadoop MapReduce es un paradigma de procesamiento de datos caracterizado por dividirse en dos fases o pasos diferenciados: Map y Reduce. Estos subprocesos asociados a la tarea se ejecutan de manera distribuida, en diferentes nodos de pro cesamiento o esclavos. Facilitar la creación de aplicaciones que transforman grandes conjuntos de datos en un solo conjunto de datos fácil de usar.
Como se ha mencionado antes, mapreduce se divide en dos fases distintas. Cada una de ellas funciona de la siguiente manera:
- La fase Map se ejecuta en subtareas llamadas mappers. Estos componentes son los responsables de generar pares clave-valor filtrando, agrupando, ordenando o transformando los datos originales.
- La fase Shuffle (sort) puede no ser necesaria. Es el paso intermedio entre Map y reduce que ayuda a recoger los datos y ordenarlos de manera conveniente para el procesamiento. Con esta fase, se pretende agregar las ocurrencias repetidas en cada uno de los mappers.
- La fase Reduce gestiona la agregación de los valores producidos por todos los mappers del sistema (o por la fase shuffle) de tipo clave-valor en función de su clave. Por último, cada reducer genera su fichero de salida de forma independiente, generalmente escrito en HDFS.
Esta herramienta nos ofrece ventajas como:
- Escalabilidad: Las empresas pueden procesar petabytes de datos almacena dos en el sistema de archivos distribuido de Hadoop (HDFS).
- Flexibilidad: Hadoop permite un acceso más fácil a múltiples fuentes de datos y múltiples tipos de datos.
- Velocidad: Con procesamiento paralelo y movimiento de datos mínimo, Hadoop ofrece un procesamiento rápido de cantidades masivas de datos.
- Simple: Los desarrolladores pueden escribir código en una variedad de len guajes, incluidos Java, C ++ y Python.
También este herramienta tiene ciertas limitaciones, entre ellas podremos hablar sobre:
- Hasta que la fase map completa su procesamiento, los reducers no empiezan a ejecutar.
- Tampoco se puede controlar su orden de ejecución.
Entre las alternativas a mapreduce encontramos Apache Pig y Apache Spark entre otras.
Antes de YARN, era MapReduce 1.0 el responsable de distribuir el trabajo. Se compone de un Job Tracker y muchos rastreadores de tareas. Job Tracker es como un gerente de taller que es responsable de interactuar con los clientes y realizar el trabajo a través de Task Trackers. El rastreador de trabajos desglosa el trabajo y distribuye piezas a varios rastreadores de tareas. Los rastreadores de tareas mantie nen Job Tracker actualizado con el estado más reciente. Si un rastreador de tareas no proporciona el estado, Job Tracker asume que el rastreador de tareas está inactivo. Apartir de entonces, Job Tracker asigna el trabajo a algún otro rastreador de tareas.
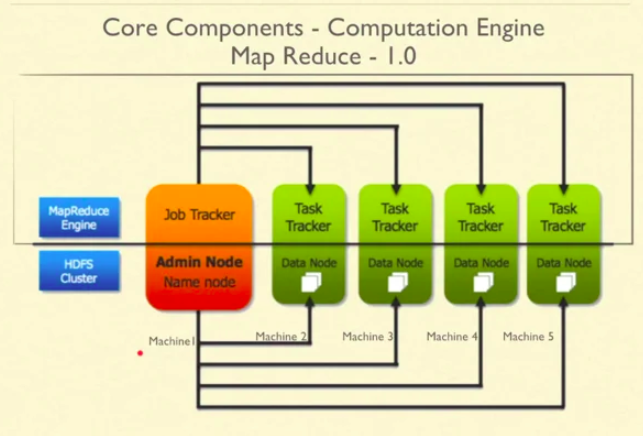
Para garantizar una carga igual en todos los rastreadores de tareas, Job Tracker realiza un seguimiento de los recursos y las tareas.
El marco MapReduce era muy restrictivo: la única forma de realizar el trabajo era utilizando el marco MapReduce. No todos los problemas eran adecuados para el tipo de modelo MapReduce. Algunos de los problemas se pueden resolver mejor utilizando otros marcos. Por eso entró en juego YARN. Básicamente, Map-Reduce 1.0 se dividió en dos grandes componentes: YARN y MapReduce 2.0. YARN solo es responsable de administrar y negociar recursos en el clúster y MapReduce 2.0 solo tiene el marco de cálculo, también llamado flujo de trabajo, que ejecuta la lógica en dos partes: mapear y reducir. MapReduce 2.0 también ordena los datos.
Esta refactorización o división dio paso a muchos otros marcos para resolver diferentes tipos de problemas, como Tez, HBase, Storm, Giraph, Spark, OpenMPI, etc.
Las ventajas de YARN son:
- Admite muchas cargas de trabajo, incluido MapReduce.
- Ahora, con YARN, la ampliación se hizo más fácil.
- MapReduce 2.0 era compatible con MapReduce 1.0. No es necesario modificar el programa escrito para MapReduce 1.0. La simple recopilación fue suficiente.
- Esto mejoró la utilización del clúster, ya que eran posibles diferentes tipos de cargas de trabajo en el mismo clúster.
- Mejoró la agilidad.
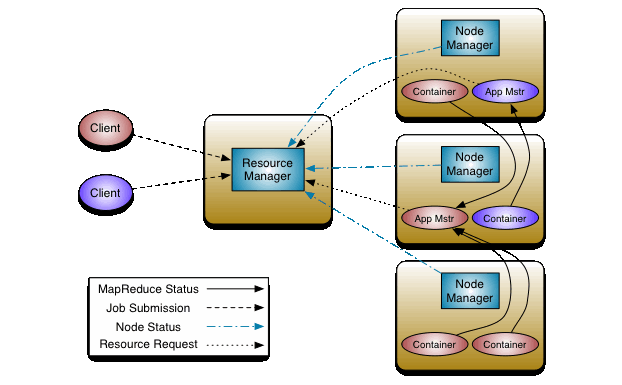
La función de Job Tracker en MapReduce 1 ahora se divide en varios componentes en Yarn:
- Resource Manager: Es la autoridad final que arbitra los recursos entre todas las aplicaciones del sistema. Se compone de: Application Master y Scheduler
- Application Master: Es responsable de aceptar las presentaciones de tra bajos, negociar el primer contenedor para ejecutar la ApplicationMaster espe cífica de la aplicación y proporcionar el servicio para reiniciar el contenedor de ApplicationMaster en caso de fallo. El ApplicationMaster por aplicación tiene la responsabilidad de negociar contenedores de recursos adecuados con el planificador, hacer un seguimiento de su estado y monitorear el progreso.
- Scheduler: Es responsable de asignar recursos a las diversas aplicaciones en ejecución, sujeto a restricciones familiares de capacidades, colas, etc. El planifi cador es un planificador puro en el sentido de que no realiza ningún monitoreo o seguimiento del estado de la aplicación. Además, no ofrece garantías sobre el reinicio de tareas fallidas debido a fallos de la aplicación o fallos de hardware. El planificador realiza su función de programación en función de los requisitos de recursos de las aplicaciones; lo hace en base a la noción abstracta de un “Contenedor” de recursos que incorpora elementos como memoria, CPU, disco, red, etc.
- Timeline Server: Mantiene la información sobre las aplicaciones actuales e históricas ejecutadas en el clúster YARN.
- El Task Tracker ahora es Node Manager: Es el agente de marco por máquina que es responsable de los contenedores, monitorea su uso de recursos e informa lo mismo al ResourceManager/Scheduler.
A medida que Hadoop ha pasado de Map Reduce a otros motores de ejecución (Spark, Tez, Flink), el "history server", diseñado con MapReduce, dejó de funcionar. Además, el "history server" solo proporciona estadísticas sobre trabajos completados y tiene o tenía problemas de escalabilidad. El "Application Timeline Server (ATS)" abordó estos problemas e introdujo el concepto de un “flujo”, que es una serie de trabajos tratados como una entidad única en lugar de un conjunto de trabajos (MapReduce).
Apache ZooKeeper y HA
ZooKeeper es un servicio de coordinación distribuido de código abierto para aplicaciones distribuidas. Expone un conjunto simple de primitivas que las aplica ciones distribuidas pueden utilizar para implementar servicios de nivel superior para sincronización, mantenimiento de configuración, grupos y nombres. Está diseñado para ser fácil de programar y utiliza un modelo de datos estilizado según la conocida estructura de árbol de directorios de los sistemas de archivos. Se ejecuta en Java y tiene enlaces tanto para Java como para C.
Los servicios de coordinación son conocidos por ser difíciles de implementar correctamente. Son especialmente propensos a errores como condiciones de carrera y bloqueo. ZooKeeper permite que procesos distribuidos coordinen entre sí a través de un espacio de nombres jerárquico compartido, organizado de manera similar a un sistema de archivos estándar. El espacio de nombres consiste en registros de datos, llamados znodes en la jerga de ZooKeeper, que son similares a archivos y directo rios. A diferencia de un sistema de archivos típico diseñado para almacenamiento, los datos de ZooKeeper se mantienen en memoria, lo que significa que ZooKeeper puede lograr cifras de alto rendimiento y baja latencia.
La implementación de ZooKeeper prioriza un acceso de alto rendimiento, altamen te disponible y estrictamente ordenado. Los aspectos de rendimiento de ZooKeeper permiten su uso en sistemas distribuidos y de gran escala. Los aspectos de confia bilidad evitan que se convierta en un punto único de falla. La ordenación estricta significa que se pueden implementar primitivas de sincronización sofisticadas en el cliente.
ZooKeeper está replicado. Al igual que los procesos distribuidos que coordina, ZooKeeper está diseñado para ser replicado en un conjunto de hosts llamado un conjunto (ensemble).
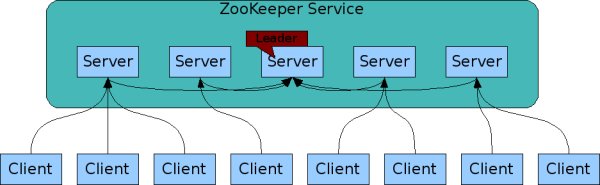
Elementos Importantes de ZooKeeper:
- ZNodes: Los ZNodes son nodos que forman un árbol jerárquico y almacenar datos en forma de estructuras de árboles. Cada ZNode puede contener datos y tener hijos. Son efímeros o persistentes. Los ZNodes efímeros desaparecen cuando la sesión que los creó termina, mientras que los persistentes permanecen en el sistema.
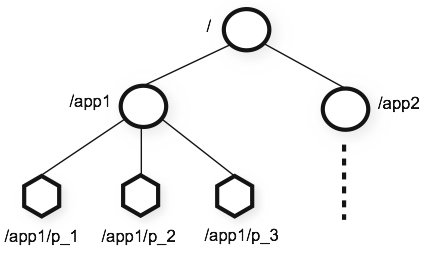
- Sessions: Cuando un cliente se conecta a ZooKeeper, se establece una sesión. La sesión tiene un identificador único, y cada sesión tiene un timeout asociado. Las sesiones son importantes para la gestión de ZNodes efímeros y watchers.
- Watchers: Son notificaciones que los clientes pueden recibir. Un cliente puede establecer un watcher en un ZNode específico, y cuando ocurre un cambio (creación, borrado, actualización), el cliente recibe una notificación.
- Ensembles: Un conjunto de servidores ZooKeeper que colaboran juntos es conocido como un ensemble. Es útil para mantener la alta disponibilidad y la tolerancia a fallos de ZooKeeper.
- Leader y Followers: En un ensemble, uno de los servidores se selecciona como líder, y los demás actúan como seguidores. El líder maneja todas las escrituras, mientras que los seguidores manejan las lecturas y participan en la elección de un nuevo líder en caso de falla.
- ACLs: Las ACLs se utilizan para controlar el acceso a los ZNodes.
Cuando hablamos de un "cliente" en el contexto de ZooKeeper, generalmente nos referimos a una aplicación o un servicio dentro de un sistema distribuido, y no a un usuario humano.
Los "watchers" son fundamentales para permitir que los clientes reaccionen y respon dan de manera dinámica y en tiempo real a los cambios en el estado o configuración dentro de un sistema distribuido.
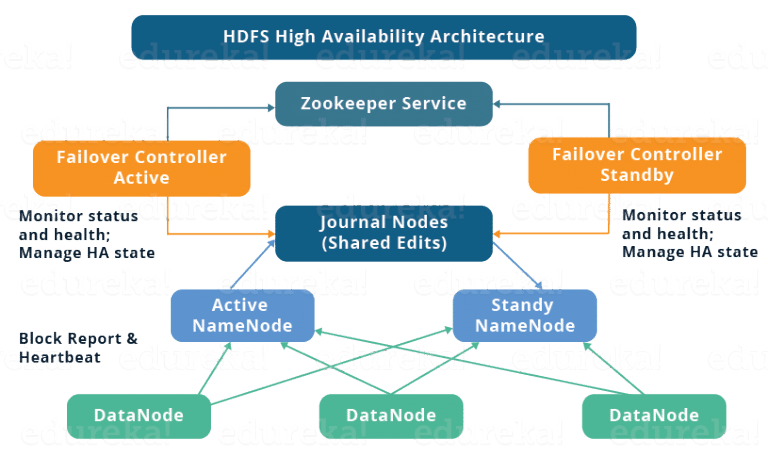
Alta disponibilidad en HDFS
La alta disponibilidad (HA) en HDFS (Hadoop Distributed File System) es una característica crítica para evitar un punto único de falla en los NameNodes. Los elementos más importantes involucrados en configurar y mantener HA en HDFS son:
- NameNodes en HA: Encontramos el namenode activo, el principal punto de contacto para todos los clientes de HDFS. Gestiona todas las operaciones de metadatos y namespaces en el clúster. En segundo lugar, tenemos el namemode en Standby que se trata de un nodo de reserva que se mantiene sincronizado con el NameNode activo. Puede asumir el rol de NameNode activo en caso de una falla.
- JournalNodes: Los JournalNodes son responsables de mantener y sincronizar los cambios en los metadatos entre el NameNode activo y los NameNodes en standby. Permiten que el NameNode en standby esté al día con los cambios recientes realizados por el NameNode activo.
- ZKFailoverController (ZKFC): Es un proceso que se ejecuta junto a cada NameNode y es responsable de monitorear el estado del NameNode. En caso de una falla en el NameNode activo, el ZKFC puede iniciar una elección de líderes para seleccionar un nuevo NameNode activo.